Most AI listing tools want you to trust the output and move on. Snap a photo, let the AI do its thing, push it live.
That works until it doesn't. And when it doesn't, you've got a listing live on eBay with the wrong product identification, a bad price, or a description that doesn't match what's in the box. Now you're dealing with returns, refunds, and negative feedback that tanks your seller metrics.
We built ListForge differently. Every item goes through a review step before anything goes live. And that review step turned out to be the most important feature in the entire platform.
What the Review Step Actually Does
When you capture an item in ListForge, AI agents go to work. They identify the product, research comparable sales across marketplaces, analyze pricing strategies, and generate listing content. This all happens in the background while you keep scanning inventory.
But none of it goes live automatically. Not by default.
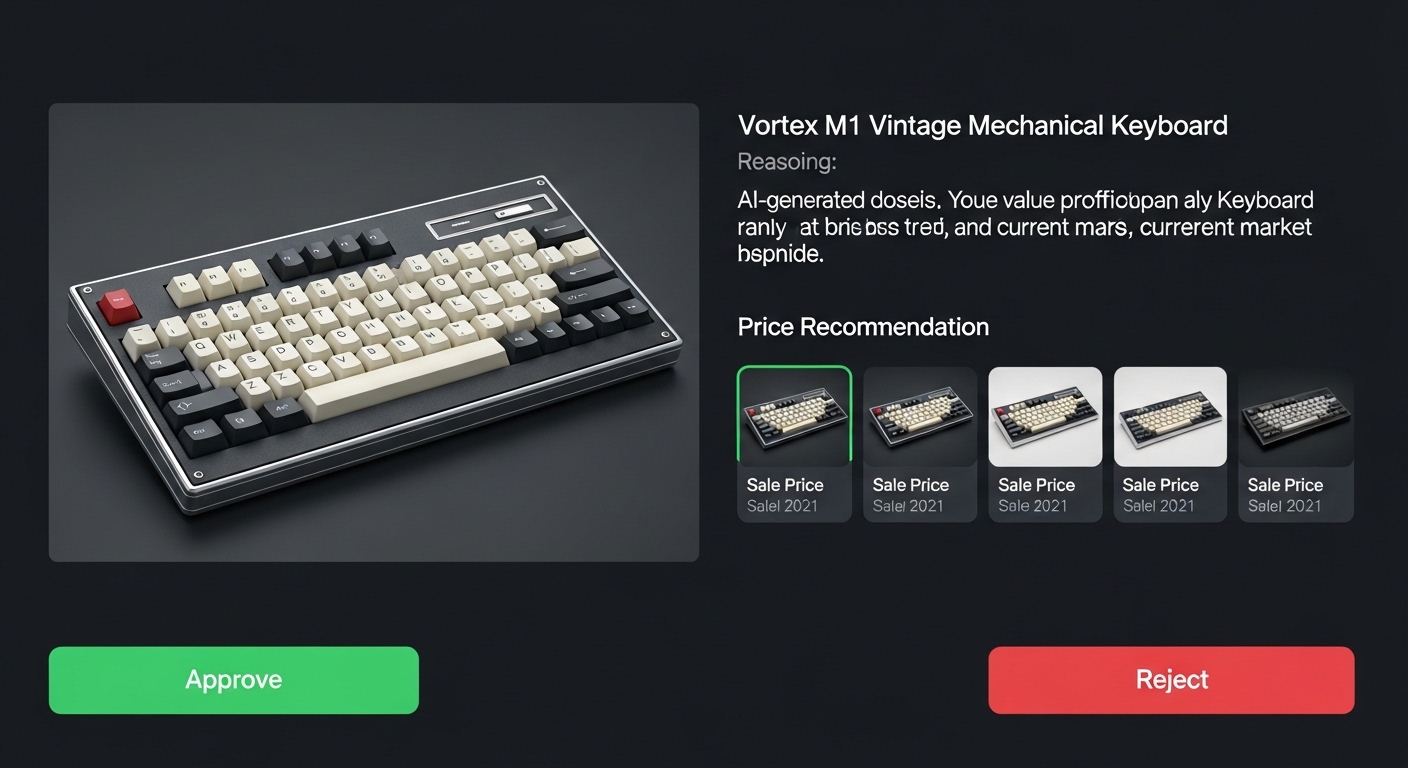
The item lands in your review queue with everything the AI found laid out in front of you. Product identification with the AI's reasoning and conviction level. Pricing recommendation with three strategies: aggressive, balanced, and premium, each with an estimated days-to-sell. Up to 10 comparable sales with prices, images, condition, and how recently they sold. Contextual warnings if something looks off, like no comps found, low pricing confidence, or a listed price significantly above the median comp.
You see everything the AI saw. You see why it made the decisions it made. And you decide whether to approve, reject, or edit.
This isn't a rubber stamp. It's a full audit of the AI's work.
The Speed Problem It Solves
The obvious question is: doesn't this slow things down? If AI is supposed to make listing faster, why add a manual step?
Because the alternative is worse. Without review, you're either spending time fixing bad listings after they're live, or you're blindly trusting AI output and hoping for the best. Both of those cost more time and money than a quick review.
The review queue is designed for speed. Keyboard shortcuts: A to approve, R to reject, E to edit, arrow keys to navigate. On mobile, it's a card-based flow. Swipe through items, tap approve or reject, move on. Most items take 5-10 seconds to review when the AI got it right. And the AI gets it right most of the time.
The key insight is that reviewing a correct result is fast. It's generating a correct result from scratch that's slow. The review step lets you move at AI speed while keeping human accuracy.
How It Trains the AI
Here's where it gets interesting. Every review decision is a training signal.
Every time you approve an item, you're telling the system: this identification was correct, this pricing was reasonable, these comps were relevant. Every time you reject, you're telling it: something was wrong here. And if you leave a comment explaining why, that's even more valuable.
We track all of this. Approval rates by conviction level. Rejection reasons. Price adjustments, where the user's final price differs from the AI's suggestion. Which pricing strategy users actually choose versus what the AI recommended. How often specific warning types appear on items that get approved versus rejected.
This data creates a continuous feedback loop. We can see exactly where the AI is strong and where it's weak. We can benchmark model changes against historical review outcomes. We can tune conviction thresholds based on real approval patterns.
The review step isn't just quality control. It's an eval system running on every single item that flows through the platform.
The Conviction System
Not all AI output is created equal. Sometimes the system identifies a product with absolute certainty: exact brand, model, UPC match, dozens of comparable sales. Other times it's working with blurry photos and a vague description, making its best guess.
ListForge quantifies this difference with conviction levels. Every identification and pricing recommendation comes with a conviction score that reflects how confident the AI is in its output.
This feeds directly into the automation settings. You can configure auto-approval thresholds: only auto-approve items where the AI's conviction is high, and route everything else to manual review. You can set different thresholds for different stages. Maybe you auto-approve high-conviction research but still want to manually review every listing before it publishes.
The system adapts to your comfort level. Start with everything in manual review. As you build trust in the AI's output for certain categories, gradually raise the automation threshold. You're always in control of how much autonomy the AI gets.
Why This Matters for Teams
If you're a solo reseller, the review step keeps you accurate. If you're running a team, it's how you scale.
The review queue is org-scoped and real-time. Multiple team members see the same queue. When someone approves or rejects an item, it updates instantly for everyone. You can assign items to specific reviewers. You can bulk approve or reject when you're moving fast.
This means you can have less experienced team members doing the initial capture and scanning, while your most knowledgeable people handle review. The AI does the heavy lifting of research and pricing. The reviewer validates the output. Nobody needs to be an expert on every product category because the AI provides the research and the comps. They just need to sanity-check it.
This is how a two-person operation starts processing hundreds of items a day without hiring a pricing specialist.
Evidence Provenance
One thing we're serious about is traceability. Every approved item has a complete evidence bundle linking it back to specific agent runs, tool calls, and evidence sources. You can trace exactly how the AI arrived at its identification and pricing.
If a listing gets a return or a complaint, you can go back and see what the AI found, what the reviewer approved, and whether the issue was in the AI's research or somewhere else in the process. This isn't just about accountability. It's about learning. Every failure is traceable, which means every failure is fixable.
We block approval entirely if the evidence bundle is missing or incomplete. No provenance, no approval. The system won't let you publish something it can't explain.
The Bigger Picture
The review step is where AI accountability meets practical business operations.
Most AI tools treat their output as a black box. You get a result. Maybe it's good, maybe it's not. You have no visibility into why the AI made the decisions it made, and no systematic way to improve it over time.
ListForge flips that. The review step gives you full transparency into the AI's reasoning. It gives the AI continuous feedback to improve. It gives teams a scalable workflow that doesn't sacrifice quality for speed. And it gives every listing a traceable audit trail from photo to published listing.
AI-generated listings are only as good as the feedback loop behind them. The review step is that feedback loop.
ListForge is currently in early access. If you're a reseller looking to list faster without sacrificing accuracy, sign up for early access and see how the review workflow fits into your process.